The simplest way(and probably one of the best) to solve a text CAPTCHA
Disclaimer: While it’s technically possible to use Tesseract OCR to attempt to crack simple text CAPTCHAs, it’s important to note that this practice is often against website terms of service. CAPTCHAs are designed to differentiate between humans and bots, and bypassing them can lead to account bans.
A CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a security measure commonly used to prevent automated programs (bots) from accessing websites or performing malicious actions. Text CAPTCHAs present distorted text characters, requiring human intervention to decipher and input the correct text. I recently came across with some articles about training machine learning models to solve CAPTCHAs. While using deep learning techniques is a promising way to solve CAPTCHAs, it requires good amount of data to improve the accuracy of the models, and it may take time to solve a CAPTCHA. After digging into the issue further, I found an easiest way to solve a simple text CAPTCHA while still maintaining high accuracy.
To achieve this, we need to use Tesseract OCR. Tesseract OCR (Optical Character Recognition) is a powerful open-source software engine that can recognize and extract text from images. While it’s a valuable tool for many legitimate purposes, it can also be used to attempt to break simple CAPTCHAs.
There are several steps involved to solve CAPTCHAs using Tesseract:
- Obtain the CAPTCHA Image:
- You can simply download the CAPTCHAs by manually saving it, or use a web scraping tool or browser extension to capture the CAPTCHA images from the website.
2. Preprocess the Image:
- Noise Reduction: Apply techniques like Gaussian blurring or median filtering to reduce noise and enhance image clarity.
- Contrast Enhancement: Adjust the contrast and brightness to make text characters more distinguishable.
- Image Segmentation: Identify and isolate individual characters within the CAPTCHA image.
3. Apply Tesseract OCR:
- Use Tesseract to analyze the preprocessed image and extract the recognized text.
Tools we need
Opencv-python
OpenCV (Open Source Computer Vision Library) is a powerful library primarily used for real-time computer vision. It provides a vast array of functions for image and video processing, object detection, and machine learning. We can install it using pip:
pip install opencv-pythonTesseract
Tesseract is an OCR engine developed by Google. We can install it using brew on Mac:
brew install tesseractAfter installing tesseract, you also need to install pytesseract which is a python wrapper for Google’s Tesseract-OCR Engine:
pip install pytesseractPreprocess the Image
Let’s first look at what CAPTCHA I was dealing with. The text CAPTCHA looks like this:

This is a simple text CAPTCHA contains only numbers. The first thing we need to do is to remove the noise. As you can see there are a lot of dots in the image which is similar to the classic “salt and pepper” noise. Salt and pepper noise is a type of image noise that appears as random black and white pixels scattered throughout an image. It’s often caused by errors during image acquisition or transmission.
Common methods for “salt and pepper” noise removal
Several techniques can be used to reduce or eliminate salt and pepper noise:
- Median filtering: Replaces each pixel with the median value of its neighboring pixels, effectively smoothing out isolated noise pixels.
- Mean filtering: Replaces each pixel with the average value of its neighboring pixels, but can blur edges and fine details.
- Adaptive filters: Adjust the filter’s parameters based on local image characteristics to preserve edges while removing noise.
Here we are going to use median filter to remove this kind of noise, because using median does the best to remove the noise while preserving the text. Median filter applies only to grayscale pictures, so let’s first read the image as grayscale:
gray = cv2.imread(filename, cv2.IMREAD_GRAYSCALE)and then apply median filter:
medianBlur = cv2.medianBlur(gray, 3)The second parameter of the medianBlur function is the size of the block that we use to calculate the median. It must be odd and greater than 1, for example: 3, 5, 7.
After applying medianBlur function, we can see the most of the noise has been reduced:
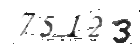
To make it look even smoother, I also applied Gaussian Blur. Gaussian blur is a widely used image processing technique that blurs an image by applying a Gaussian function to each pixel. This results in a smooth, natural-looking blur that reduces noise and detail.
How it works:
- Gaussian Kernel: A Gaussian kernel is created, which is a matrix of weights that follow a Gaussian distribution.
- Convolution: The kernel is convolved with the image, meaning it’s multiplied with each pixel and its neighbors, weighted by the kernel values.
- Blurring Effect: The weighted sum of the neighboring pixels produces a blurred value for the central pixel.
I am not going to go too deep on this, but by carefully selecting the size and standard deviation of the Gaussian kernel, you can control the degree of blurring and its impact on the image.
Here is the result after applying Gaussian blur:
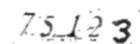
Apply Tesseract OCR
Now we can apply Tesseract to identify the actual text in the CAPTCHA:
txt = pytesseract.image_to_string(gaussianBlur, config='--psm 8 --oem 3 -c tessedit_char_whitelist=0123456789 --dpi 70')PSM means Page Segmentation Modes. If you know which mode fits your input, it can help greatly identify the text.
Here are the modes supported:
$ tesseract --help-psm
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR. (not implemented)
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.Here are the OEM(OCR Engine Mode) supported:
$ tesseract --help-oem
OCR Engine modes:
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.If you know what characters are used in the CAPTCHA, you can provide the character whitelist in the command with -c tessedit_char_whitelist.
The complete code looks like this:
import cv2
import os
import pytesseract
import sys
image = cv2.imread(filename)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
medianBlur = cv2.medianBlur(gray, 3)
gaussianBlur = cv2.GaussianBlur(medianBlur, (3,3), 0)
txt = pytesseract.image_to_string(gaussianBlur, config='--psm 8 --oem 3 -c tessedit_char_whitelist=0123456789 --dpi 70')See how simple this method is? With Simply 5 lines of code, we can decode a text CAPTCHA with only numbers.
Now let’s see what the results are with this method.
Results
I gathered 10 images to test how this works, and the result is quite satisfactory:
% python tesseract.py
--- 22807.png ---
Captcha solution: 07
Captcha solution is wrong!
--- 48776.png ---
Captcha solution: 48776
Captcha solution is correct!
--- 02655.png ---
Captcha solution: 02655
Captcha solution is correct!
--- 75123.png ---
Captcha solution: 75123
Captcha solution is correct!
--- 55567.png ---
Captcha solution: 85567
Captcha solution is wrong!
--- 03867.png ---
Captcha solution: 03867
Captcha solution is correct!
--- 97962.png ---
Captcha solution: 67962
Captcha solution is wrong!
--- 06946.png ---
Captcha solution: 06946
Captcha solution is correct!
--- 70804.png ---
Captcha solution: 70804
Captcha solution is correct!
--- 53162.png ---
Captcha solution: 53162
Captcha solution is correct!As you can see, out of 10 images, 7 CAPTCHAs are recognized correctly. This is amazing considering the simplicity of the method and its accuracy. Even with some sophisticated machine learning model, you may not achieve the same accuracy as these lines of codes do. Of course this is just a simple text CAPTCHA, but with this you can try to extend it to solve more complicated CAPTCHAs.
Additional methods
There are other functions that worth exploring, although I did not find significant improvement of the accuracy with these function in the example CAPTCHAs. However, they may still be useful for other use cases.
pyrMeanShiftFiltering
PyrMeanShiftFiltering is a powerful image processing technique in OpenCV that combines image pyramid decomposition with mean-shift clustering to perform spatial and color segmentation.
After applying PyrMeanShiftFiltering function, the image looks like this:

You can see that most of the noise around the edge of the image is blurred. We may combine this function together with others to achieve higher accuracy. Since PyrMeanShiftFiltering takes into account colors, we may use this before other methods such as median filtering which requires grayscale images.
cv2.threshold
cv2.threshold is a fundamental function in OpenCV for image thresholding. It’s used to convert a grayscale image into a binary image by classifying pixels based on a threshold value. We may use this function to further reduce noise and make the text clearer.
How it works:
- Threshold Value: A threshold value is specified.
- Pixel Comparison: Each pixel’s intensity value is compared to the threshold.
- Binary Classification:
- If the pixel value is greater than or equal to the threshold, it’s set to a maximum value (often 255, representing white).
- If the pixel value is less than the threshold, it’s set to a minimum value (often 0, representing black).
Different Thresholding Types:
OpenCV provides various thresholding types:
- BINARY: Sets pixel values to 0 or maximum value based on the threshold.
- BINARY_INV: Inverts the binary thresholding result.
- TRUNC: Truncates pixel values greater than the threshold to the threshold value.
- TOZERO: Sets pixel values less than the threshold to 0.
- TOZERO_INV: Inverts the TOZERO thresholding result.
Otsu’s Method: A popular technique for automatically determining the optimal threshold value is Otsu’s method. It calculates the threshold value that minimizes the weighted sum of variances of the two classes (pixels below and above the threshold).
cv2.erode
cv2.erode is a function in OpenCV used for morphological erosion, a fundamental operation in image processing. It’s particularly useful for removing small objects, noise, or irregularities from binary images.
How it works:
- Kernel: A structuring element, often a small matrix of ones and zeros, is defined.
- Iteration: The kernel is scanned over the image, pixel by pixel.
- Erosion: A pixel in the original image is considered 1 (foreground) only if all the pixels under the kernel are 1. Otherwise, it’s eroded to 0 (background).
cv2.dilate
cv2.dilate is an OpenCV function used for morphological dilation, a technique to expand the boundaries of objects in an image. It’s often used in conjunction with erosion to perform various image processing tasks. We may use this function after applying other function to make the text clearer.
How it works:
- Kernel: A structuring element (kernel) is defined, typically a small matrix of ones and zeros.
- Iteration: The kernel is scanned over the image, pixel by pixel.
- Dilation: A pixel in the original image is considered 1 (foreground) if at least one pixel under the kernel is 1. This effectively increases the size of objects in the image.
This is what is looks like after applying dilation on the above example:
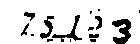
Conclusions
In this article, I talked about the tools and functions that are useful for text recognition in an image. If you find other method that are useful, please let me know by leaving comments. Hope this article can be helpful for those who are interested in image processing!